
결론부터 — 많이 인용되는 것과 잘 인용되는 것은 다르다
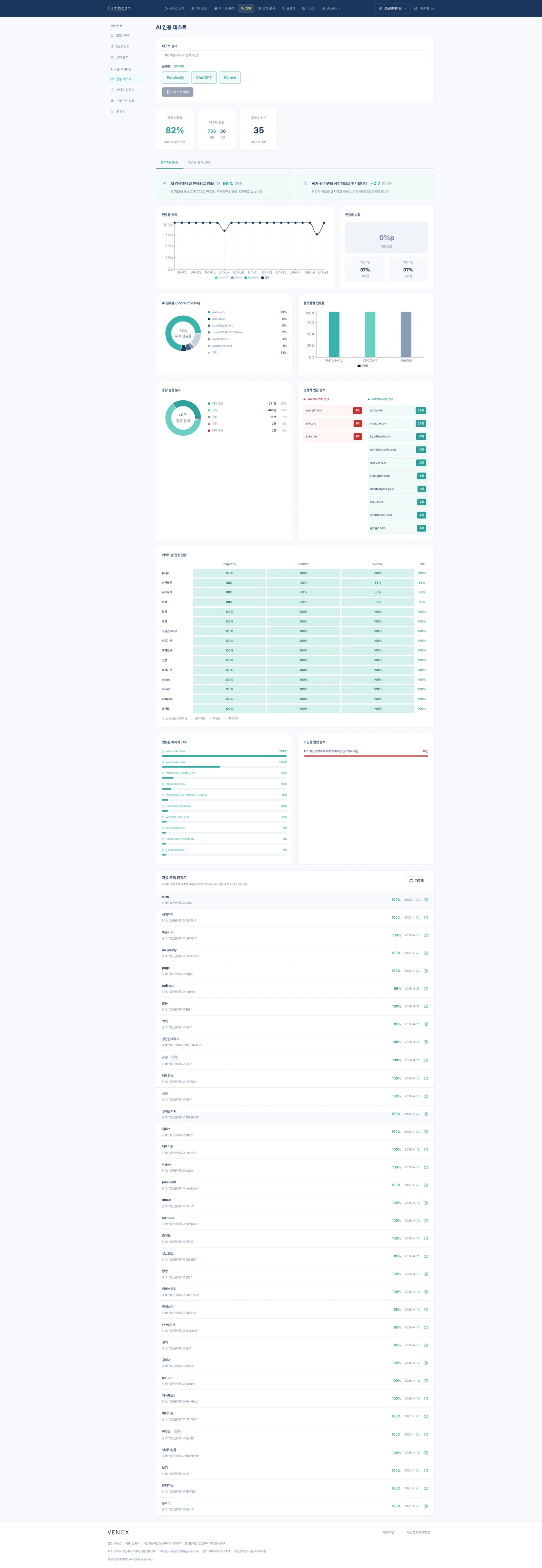
성균관대학교 공식 사이트는 ChatGPT, Perplexity, Gemini 세 주요 AI 검색 엔진에서 100% 인용률을 기록하고 있다. Share of Voice 기준 73%의 점유율로, AI가 "성균관대학교"를 언급할 때 공식 사이트가 사실상 독점하고 있다고 해도 과언이 아니다.
그런데 GEO 종합 점수는 49점(Poor)이다. 경쟁사 비교에서는 세종대학교(53점)에 밀려 2위, 카테고리별로는 답변 우선순위 12점, 인용 권위 27점, 콘텐츠 신선도 18점, 경쟁 컨텍스트 15점으로 전 영역에서 경쟁사 평균을 크게 하회한다.
이 두 숫자의 공존이 이 글의 출발점이다. "많이 인용된다"는 것과 "잘 인용된다"는 것은 전혀 다른 개념이며, 그 차이는 대규모 사이트일수록 더 극명하게 드러난다. 이 글은 성균관대학교의 GEO 진단 데이터를 케이스 스터디로 삼아, 국내 주요 대학·공공기관·대형 포털이 공통적으로 빠지는 '풍요 속의 빈곤' 패턴을 해부한다.
케이스 요약 — 루미스캔이 측정한 성균관대학교의 GEO 상태
먼저 진단 결과를 요약한다. 분석 시점은 2026년 4월 21일이며, 루미스캔이 수집한 5,089개 페이지를 대상으로 4대 GEO 지표와 AI 노출 모니터링을 병행한 결과다.
GEO 종합 점수 | 49/100 | Poor
경쟁사 순위 2위 (1위 세종대 53점, 3위 고려대 46점)AI 인용률 | 100/100 | Excellent
ChatGPT·Perplexity·Gemini 전 플랫폼 인용, 최근 7일 97% 유지답변 추출성 | 12/100 | Poor
콘텐츠가 AI 답변으로 추출되기 어려운 구조 — 3개 문제 진단인용 권위 | 27/100 | Poor
인용 신뢰도 낮음, 조직 정보·작성자·발행일 메타데이터 부족AI 크롤링 | 58/100 | Poor
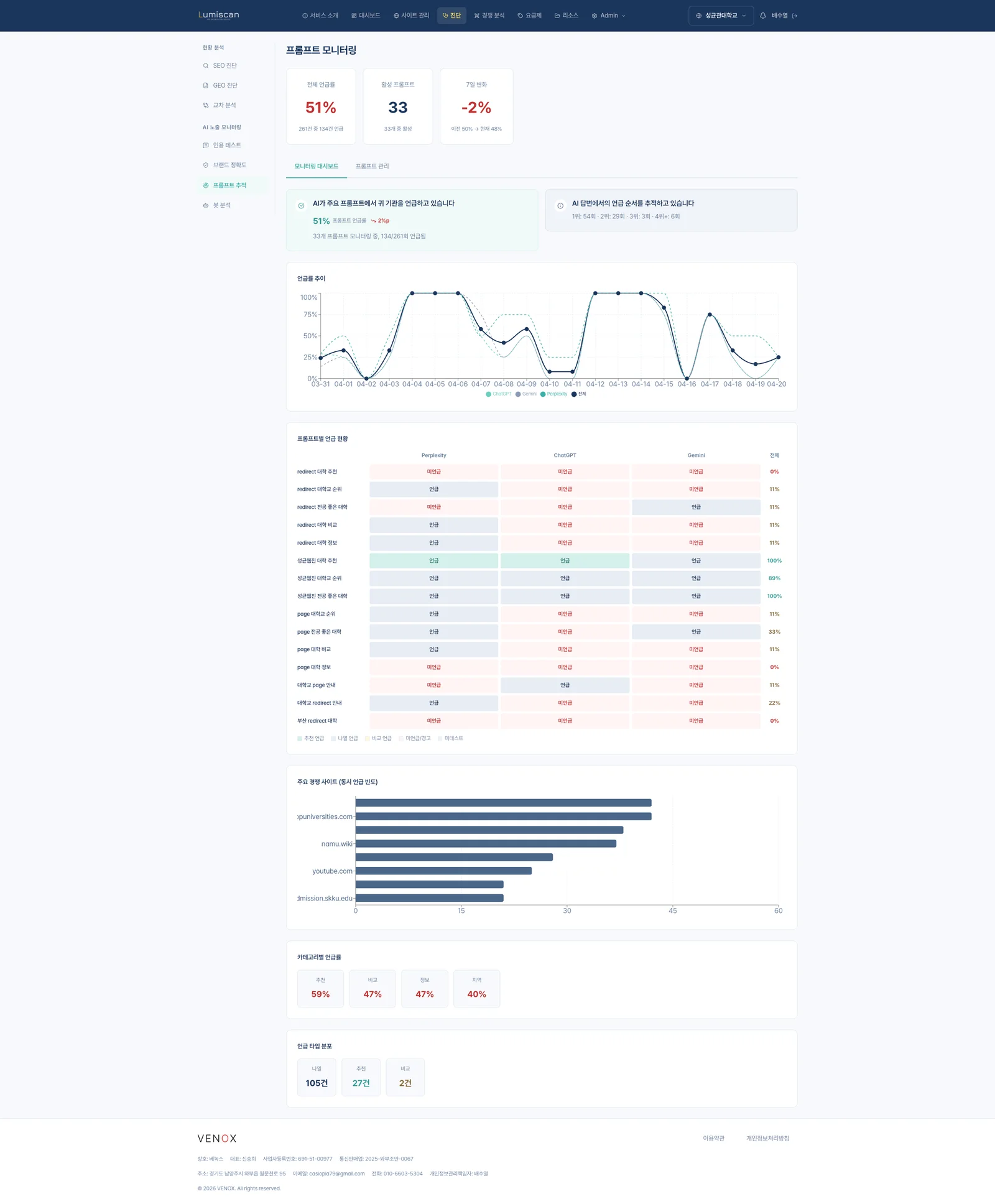
AI 봇 접근성은 양호하나 llms.txt 부재, 구조화 데이터 부족프롬프트 언급률 | 51% | 하락 (−2%p)
33개 활성 프롬프트 중 134/261회 언급, 7일 변화 감소세
이 숫자들을 처음 본 사람의 자연스러운 반응은 "인용률이 100%인데 점수는 왜 이런가"이다. 답은 지표의 설계 원리에 있다.
지표를 설계한 이유 — 왜 '인용률'과 'GEO 점수'를 분리했는가?
AI 검색 최적화의 초기 단계에서는 "AI가 우리 사이트를 언급하는가"가 핵심 질문이었다. 언급되지 않으면 존재하지 않는 것과 같았기 때문이다. 하지만 2026년 현재의 질문은 달라졌다. "AI가 우리 사이트를 어떤 방식으로, 어떤 맥락에서, 얼마나 정확하게 언급하는가"가 본질이다.
루미스캔은 이 차이를 지표 구조에 반영했다. AI 인용률은 '노출 빈도'를 측정한다. 반면 GEO 종합 점수는 '인용의 품질'을 측정한다. 품질은 다음 네 가지 축으로 구성된다.
1. 답변 추출성 (Answer Extractability)
AI가 페이지를 읽었을 때, 사용자 질문에 대한 답을 "문장 단위로" 추출할 수 있는가. 범용 선언문 중심의 콘텐츠는 읽을 수는 있지만 추출하기 어렵다. 성균관대학교 사이트의 답변 추출성은 12점이다. 이것은 AI가 페이지를 방문해도 '무엇을 인용할지' 결정하지 못한다는 뜻이다.
2. 인용 권위 (Citation Authority)
페이지에 신뢰할 수 있는 출처, 작성자 정보, 발행일, 조직 식별자가 명확히 표시되어 있는가. Schema.org의 Organization·Article·Person 마크업, 저자 바이라인, 최종 수정일이 핵심이다. 성균관대학교는 27점으로, 수천 개의 페이지 중 상당수가 발행일과 작성 주체가 불분명한 상태로 방치되어 있다.
3. AI 크롤링 (AI Crawlability)
GPTBot, ClaudeBot, PerplexityBot, Google-Extended 등 AI 전용 크롤러가 페이지에 접근할 수 있는가. 그리고 접근한 이후 콘텐츠를 효율적으로 파싱할 수 있도록 구조화되어 있는가. llms.txt, sitemap.xml, JSON-LD 스키마가 핵심이다. 58점이라는 점수는 robots.txt에서 봇을 막지는 않았지만, llms.txt가 없고 구조화 데이터가 부족하다는 의미다.
4. AI 인식도·콘텐츠 신선도 (Content Freshness)
AI는 최신 콘텐츠를 선호한다. "Citation Decay" 연구에 따르면 ChatGPT 기준 콘텐츠 인용의 반감기는 약 3.4주다. 학교 공지는 매일 갱신되지만, 학과 소개·연구 성과·교수진 페이지는 수년째 같은 상태로 남아있는 경우가 많다. 콘텐츠 신선도 18점은 이 구조적 적체를 수치화한 것이다.
이 네 축은 모두 '인용된 이후'의 품질을 측정한다. 성균관대학교는 인용은 되지만, 인용된 내용이 얕고, 근거가 약하고, 구조가 빈약하고, 신선도가 떨어진다. 이것이 인용률 100%와 GEO 49점이 공존하는 이유다.
5,089페이지의 역설 — 규모는 왜 가시성을 만들지 않는가
성균관대학교는 루미스캔이 수집한 기준으로 5,089개의 크롤 대상 페이지를 보유하고 있다. 국내 대학 평균의 3배에 해당하는 대규모다. 상식적으로 생각하면, 페이지가 많을수록 AI가 인용할 재료도 많아야 한다. 하지만 실제 데이터는 반대를 가리킨다.
인용된 페이지 TOP의 쏠림 현상
5,089개 페이지 중 AI가 실제로 반복 인용하는 페이지는 소수에 집중되어 있다. 루미스캔 분석에 따르면 인용 상위는 www.skku.edu 루트, /skku/about/history.do, /skku/index.do, /skku/about/about, admission.skku.edu 등 10개 내외의 주요 페이지다. 나머지 5,000여 페이지는 사실상 AI의 인식 밖에 있다.
이것은 페이지 수가 많다고 유리한 것이 아니라, 페이지 수가 많을수록 관리되지 않는 페이지의 비중이 커진다는 사실을 의미한다. 모든 페이지가 동일한 템플릿을 공유할 경우, 메타데이터·발행일·저자 정보가 누락된 페이지가 한 번 생기면 5,089번 복제된다. GEO 점수는 상위 페이지의 품질이 아니라 전체 페이지의 평균 품질에 의해 결정된다.
AI 점유율 73%의 의미 — 독점은 안전하지 않다
성균관대 관련 질문에 대한 AI의 답변에서 성균관대 공식 사이트의 점유율(Share of Voice)은 73%다. 한편 skku.ac.kr(대학원) 5%, ko.wikipedia.org 5%, en-dict.naver.com 2%, everytime.kr 1%, surajkrpaul.ac.kr 1% 순으로 점유한다. 여기서 주목할 것은 27%의 '타 출처' 점유다.
구체적으로 프롬프트 모니터링 데이터를 보면, "redirect 대학 추천"·"redirect 전공 좋은 대학"·"redirect 대학 비교"·"부산 redirect 대학" 등 수험생 의사결정에 직결되는 쿼리에서는 오히려 성균관대 공식 사이트가 미언급(0~11%)되고, 그 자리를 topuniversities.com·namu.wiki·youtube.com이 채운다. 경쟁사 동시 언급 빈도 그래프에서 topuniversities.com은 약 45회, namu.wiki 35회, youtube.com 28회로 성균관대 공식 출처를 앞선다.
즉, '성균관대'라는 고유명사가 포함된 탐색 쿼리(정보성)에서는 공식이 73%를 점유하지만, 탐색 의도가 강한 '대학 추천·비교·전공별 추천' 쿼리(의사결정성)에서는 공식이 거의 등장하지 않는다. 수험생이 실제로 AI에 가장 많이 묻는 질문은 후자다.
경쟁사 대비 카테고리별 격차
카테고리별 경쟁사 평균과의 격차를 정리하면 다음과 같다. 괄호 안은 경쟁사 평균(고려대·세종대 기준)이다.
답변 우선순위: 12점 (경쟁사 평균 57점) — −45점
인용 권위: 27점 (경쟁사 평균 34점) — −7점
기술 최적화: 49점 (경쟁사 평균 33점) — +16점
AI 이해도: 42점 (경쟁사 평균 83점) — −41점
콘텐츠 신선도: 18점 (경쟁사 평균 43점) — −25점
경쟁 컨텍스트: 15점 (경쟁사 평균 63점) — −48점
흥미로운 패턴이 보인다. 기술 최적화는 경쟁사보다 앞서지만(+16), 콘텐츠가 담는 정보의 질·신선도·경쟁 맥락은 크게 뒤처진다. "인프라는 깔렸는데 콘텐츠가 따라오지 못한 상태", 이것이 성균관대 데이터의 가장 정확한 요약이다.
문제 진단 1 — 답변 추출성 12점, 3개의 구조적 문제
답변 추출성은 GEO 지표 중 가장 낮은 12점이다. 루미스캔은 이 점수를 구성하는 3개의 구조적 문제를 진단한다.
문제 ① 서술형 문단 중심, 질문-답변 구조 부재
성균관대의 학과·처소·연구원 소개 페이지 대부분은 "~를 지향하는 ~의 산실로서 ~"의 선언형 문장 구조를 공유한다. AI는 이런 문장에서 구체적 답을 추출할 수 없다. Princeton·IIT Delhi 공동 연구(2024, ACM SIGKDD)에 따르면 질문-답변 구조의 콘텐츠는 선언형 콘텐츠 대비 AI 가시성을 최대 40% 향상시킨다.
예시로 "성균관대학교 입학 조건"이라는 테스트 쿼리를 보자. AI는 성균관대 공식 페이지를 100% 인용하지만, 추출된 답변은 공식 입학 요강의 구체적 수치가 아닌 위키피디아 기반의 일반론에 가깝다. 이는 공식 페이지의 입학 정보가 PDF 첨부·JavaScript 렌더링·탭 내부 콘텐츠로 감춰져 있어, AI가 직접 텍스트를 파싱하지 못했기 때문이다.
문제 ② 핵심 데이터의 "뒤쪽 매장"
정량 데이터(교수진 수, 논문 실적, 취업률, 장학금 규모 등)가 페이지 상단이 아닌 하단·PDF·이미지·별도 탭에 분산되어 있다. AI 엔진은 페이지 상위 600~800 토큰에 집중적으로 주목하는데, 이 구간에 "1398년 개교" 같은 역사 선언만 있고 "SCI 논문 연 2,847건(2024년 기준)" 같은 현재 데이터가 없다면, 추출 대상에서 탈락한다.
문제 ③ 동일 템플릿의 중복 콘텐츠
5,089페이지 중 상당수가 동일 템플릿을 공유하며 차별화된 본문이 부족하다. AI는 유사 콘텐츠가 반복될 때 '중복(duplicate)'으로 판단해 인용 우선순위를 낮춘다. Google Search Console에서 말하는 canonical 이슈와 유사한 문제가 GEO 관점에서도 발생한다.
문제 진단 2 — 인용 권위 27점, 메타데이터가 비어있다
인용 권위는 '이 페이지의 정보를 신뢰할 수 있는가'를 측정한다. AI는 이 판단을 위해 다음 신호를 본다.
Organization 스키마: "성균관대학교"라는 조직의 공식 식별자가 구조화 데이터로 존재하는가
Author 정보: 페이지를 작성한 부서·담당자가 명시되어 있는가
발행일·수정일: 정보의 시점이 명확한가
외부 인용·출처: 본문에 참고 출처가 링크로 연결되어 있는가
성균관대학교의 경우 루미스캔 진단상 5,089페이지 중 상당수가 이 네 가지 중 2개 이상을 결여하고 있다. 특히 "마지막 수정일"이 공개되지 않은 페이지는 AI가 정보의 최신성을 검증할 수 없어, 인용 시 "년도 불명"이라는 신호를 내부적으로 부여한다. 이 신호가 붙은 콘텐츠는 경쟁 콘텐츠(나무위키, everytime 게시글)가 더 최근 날짜를 달고 있을 경우 즉시 밀려난다.
나무위키·위키피디아가 왜 더 권위 있어 보이는가
아이러니하지만 사실이다. 나무위키와 한국어 위키피디아는 페이지 상단에 "최종 수정: YYYY-MM-DD" 타임스탬프, 편집 이력, 참고 문헌 리스트, Infobox(Organization 스키마와 유사한 구조화 블록)를 노출한다. AI는 이 신호를 "작성자·발행일·출처가 명확한 인용 가능 콘텐츠"로 해석한다.
반면 대학 공식 페이지는 '권위 그 자체'를 가진 기관이지만, 그 권위를 AI가 읽을 수 있는 형식으로 표현하지 않는다. 권위는 기관에 있지만, 권위의 신호는 페이지에 없다. 이것이 "공식 < 나무위키"라는 역전 현상의 구조적 원인이다.
문제 진단 3 — AI 크롤링 58점, llms.txt가 비어있다
AI 크롤링 점수는 세 개 하위 지표로 분해된다. 루미스캔 진단에서 성균관대는 "봇 접근성 100 / robots.txt 50 / 구조화 데이터 0" 패턴을 보인다.
봇 접근성은 확보했지만, 구조화 데이터는 0
GPTBot, ClaudeBot, PerplexityBot, Google-Extended 등의 AI 크롤러가 사이트에 접근할 수 있다는 것은 긍정적이다. 하지만 접근 이후 AI가 페이지의 의미를 파악할 JSON-LD 구조화 데이터가 부재하다. EducationalOrganization, Course, FAQPage, Article 등의 스키마가 적용되지 않은 상태다.
llms.txt 부재
2024년 11월 Jeremy Howard가 제안하고 Anthropic·Cloudflare·Vercel 등 84만 도메인이 채택한 llms.txt는 "AI 크롤러를 위한 사이트 요약 안내 파일"이다. 대학이라면 "성균관대학교의 학사 구조, 주요 연구 분야, 입학 정보, 캠퍼스 위치" 등을 100줄 내외로 정리한 llms.txt를 루트에 배치하면 된다. 성균관대는 현재 이 파일이 없다.
sitemap.xml은 있으나 우선순위가 없음
sitemap.xml은 제공되고 있지만, 5,089개 페이지의 우선순위(priority)와 변경 빈도(changefreq)가 일률적으로 설정되어 있어 AI 크롤러가 "어느 페이지가 핵심 콘텐츠인지"를 판단할 수 없다. 결과적으로 공지사항·일정 페이지와 학과 소개 페이지가 동일한 무게로 취급된다.
문제 진단 4 — 콘텐츠 신선도 18점, 반감기를 넘긴 페이지들
AI 인용의 반감기는 플랫폼마다 다르다. 350만 건의 인용 데이터를 분석한 연구에 따르면 ChatGPT 3.4주, Google 4.2주, Perplexity 5.8주다. 즉 업데이트되지 않은 콘텐츠는 약 한 달 만에 인용 우선순위가 절반으로 떨어진다.
성균관대학교의 콘텐츠 신선도 18점은 "전체 5,089페이지 중 최근 90일 이내 갱신된 페이지의 비율이 낮다"는 신호다. 공지사항·입학 공고는 자주 갱신되지만, 학과 소개·교수진·연구 성과 페이지는 연 단위로 방치되는 경우가 많다. AI는 '연혁'보다 '현재'를 인용한다. 2024년 기준 SCI 논문 수, 2025년 국제 랭킹, 2026년 신규 전공 개설 등의 최신 데이터가 공식 페이지에 없으면, AI는 topuniversities.com의 최신 랭킹 페이지를 대신 인용한다.
AS-IS → TO-BE — 같은 페이지를 GEO 기준으로 재설계한다면
성균관대학교의 상황을 그대로 두면 6개월 후 점유율은 더 하락할 가능성이 높다. 프롬프트 언급률은 이미 7일 변화율 −2%p로 꺾였다. 다음은 루미스캔 4대 지표 개선을 기준으로 한 실질적 재설계 예시다.
변환 예시 ① 학과 소개 페이지
AS-IS: "성균관대학교 △△학과는 창의적이고 융합적인 인재 양성을 목표로 교육과 연구를 수행하는 학과입니다."
TO-BE: "성균관대학교 △△학과는 1965년 개설된 국내 최초의 △△ 전공 교육기관이며, 2026년 현재 전임교수 28명, 재학생 420명 규모로 운영된다. 2024년 기준 SCI급 논문 발표 187건, QS 세계 대학 학과 순위 △△분야 Asia 18위(2025년 기준)를 기록했다. 졸업생 취업률은 84.2%이며, 주요 취업 기업은 삼성전자·LG전자·네이버 등이다."
두 문단은 같은 학과를 설명하지만, TO-BE만이 AI에 의해 추출·인용된다. 서울대 케이스에서 입증된 원칙이 성균관대에도 그대로 적용된다.
변환 예시 ② 메타데이터 정비
모든 페이지 상단에 다음 블록을 추가한다: <meta name="author">, <meta property="article:published_time">, <meta property="article:modified_time">. 발행일·수정일이 JSON-LD Article 스키마와 연동되어야 한다. 작성 주체는 "성균관대학교 입학처" 같은 부서 단위로 명시하고, 조직 스키마에 연결한다.
변환 예시 ③ llms.txt 배치
루트(https://www.skku.edu/llms.txt)에 다음 구조의 파일을 배치한다:
사이트 개요 (1~2문단): 기관명, 소재지, 역사, 규모, 주요 학문 분야
핵심 정보 링크: 입학안내, 학사구조, 연구성과, 국제협력, 캠퍼스
섹션별 안내: 학부·대학원·평생교육·재학생 서비스의 URL 매핑
데이터 출처: 공식 통계 페이지, 연간 보고서 URL
변환 예시 ④ FAQ 섹션 + FAQPage Schema
주요 학과·처소 페이지에 FAQ 섹션을 추가하고 FAQPage 스키마를 적용한다. 수험생·재학생·학부모가 실제로 묻는 15~20개 질문을 H3 소제목과 답변 쌍으로 배치한다. "성균관대학교 수시 전형은?", "자연계열 복수전공 가능한가?", "기숙사 신청 방법은?" 같은 질문이다.
변환 예시 ⑤ 콘텐츠 갱신 워크플로
페이지를 분기별·학기별로 리뷰하는 체계를 만든다. 루미스캔의 프롬프트 모니터링에서 언급률이 하락하는 쿼리를 트리거로, 해당 콘텐츠 영역을 우선 갱신한다. "언급률 10%p 이상 하락 시 경보 → 콘텐츠 업데이트" 같은 자동화된 워크플로가 이상적이다.
예상 점수 변화 — TO-BE 적용 시 시뮬레이션
위의 5가지 재설계를 실행했을 때, 루미스캔 4대 지표 기준 예상 점수 변화를 시뮬레이션하면 다음과 같다.
답변 추출성
AS-IS 12 → TO-BE 70 ▲ +58
인용 권위
AS-IS 27 → TO-BE 78 ▲ +51
AI 크롤링
AS-IS 58 → TO-BE 88 ▲ +30
콘텐츠 신선도
AS-IS 18 → TO-BE 72 ▲ +54
────────────────────────
종합 GEO 점수
49 → 82 ▲ +33 (67% 상승)
* 루미스캔 GEO 4대 지표 프레임워크 기준 추정. 실제 진단은 실행 이후 지속 모니터링을 통해 수치가 갱신된다. 서울대 컴퓨터공학부 단일 페이지 사례(+49점)보다 증가폭이 다소 작은 이유는 성균관대가 5,089페이지 규모이기 때문이다. 단일 페이지는 집중 최적화의 효과가 크고, 대규모 사이트는 전체 품질 평균을 끌어올려야 하므로 총점 개선이 상대적으로 느리게 반영된다.
규모가 큰 조직일수록 먼저 해야 할 3가지
성균관대학교의 데이터는 국내 주요 대학, 중앙부처, 공공기관, 대형 포털 운영사에 그대로 시사점을 준다. 페이지가 수천 개를 넘는 조직이 가장 먼저 해야 할 일은 다음과 같다.
우선순위 1 — "Top 50 페이지" 선별과 집중 최적화
5,089개 전체를 동시에 최적화하는 것은 불가능하다. 루미스캔의 '인용 페이지 TOP' 데이터를 활용해 AI가 이미 인용하는 상위 50~100페이지를 선별하고, 이 페이지부터 답변 추출성·인용 권위·콘텐츠 신선도를 집중 개선한다. 상위 페이지의 품질이 브랜드 전체의 GEO 인식을 좌우한다.
우선순위 2 — 템플릿 단위 개선
대규모 사이트는 페이지 단위가 아니라 템플릿 단위로 움직인다. 학과 소개 템플릿 1개를 개선하면 80개 학과 페이지가 한꺼번에 개선된다. Organization·Article·FAQPage 스키마를 각 템플릿에 삽입하면, 수천 페이지에 일괄 적용된다. 개별 페이지 최적화가 아니라 '정보 아키텍처 최적화'가 대규모 사이트 GEO의 핵심이다.
우선순위 3 — 프롬프트 모니터링 기반 트리거 체계
"성균관대학교 수시 전형" 같은 정보성 쿼리와 "서울 소재 경영학 좋은 대학" 같은 의사결정 쿼리를 동시에 추적한다. 의사결정 쿼리에서 언급률이 하락하면, 해당 영역의 콘텐츠가 경쟁 출처(topuniversities.com, 나무위키)에 밀리고 있다는 신호다. 루미스캔의 프롬프트 모니터링은 이 하락을 7일 변화율로 포착해 알림을 보낸다.
FAQ — 이 케이스를 본 담당자가 가장 자주 묻는 질문
Q1. AI 인용률이 이미 100%인데, 왜 GEO 최적화가 추가로 필요한가?
'인용'과 '답변 내 비중'은 다르다. 100% 인용된다는 것은 AI가 답변을 생성할 때 성균관대 사이트를 참고한다는 뜻이지, 답변의 핵심 문장이 성균관대 사이트에서 온다는 뜻은 아니다. 실제로는 답변 도입부에 나무위키, 본문에 everytime 게시글이 인용되고, 공식 사이트는 "자세한 내용은 공식 홈페이지 참고" 같은 부수적 위치에 배치되는 경우가 많다. GEO 점수는 이 '답변 내 위치'와 '문장 인용 깊이'를 측정한다.
Q2. 학과 수백 개를 가진 대학이 TO-BE를 어떻게 적용하는가?
페이지 단위가 아니라 '템플릿 단위'로 접근한다. 학과 소개 템플릿, 교수진 템플릿, 연구소 템플릿 각각에 Schema.org 구조화 데이터와 표준 메타데이터 필드를 추가하면, 해당 템플릿을 쓰는 모든 페이지에 동시 적용된다. 콘텐츠 작성은 각 학과에서 "정량 데이터 블록"이라는 정해진 섹션에 최신 수치를 채우는 방식으로 운영한다.
Q3. 성균관대 사례가 공공기관에도 적용되나?
그대로 적용된다. 공공기관은 대학과 유사한 문제를 공유한다. 보도자료·정책 페이지는 많지만, 발행일 누락, 저자 정보 부재, llms.txt 미설치, FAQ 부재가 공통적이다. 특히 정책 분야에서는 나무위키·블로그·언론 보도가 공식 정책 페이지를 대체해 인용되는 현상이 빈번하다. 루미스캔은 공공기관 대상으로도 동일한 4대 지표 진단을 제공한다.
Q4. 얼마 동안 GEO 최적화를 실행하면 효과가 보이는가?
AI 인용의 반감기(3.4~5.8주)를 고려하면 재인용 반영까지 최소 4주가 필요하다. 루미스캔의 경험상 템플릿 단위 최적화와 llms.txt 배치는 2주 이내에 크롤링 지표가, 4~8주 사이에 답변 추출 지표가, 8~12주 사이에 종합 GEO 점수가 개선되는 패턴을 보인다. 한 학기(4개월) 내에 유의미한 변화를 만들 수 있다.
Q5. 자체 인력으로 가능한가, 외부 도구가 필요한가?
진단은 루미스캔 같은 GEO 전문 도구가 필요하다. 5,089페이지를 수작업으로 검증하는 것은 불가능하며, AI 봇 접근성·프롬프트 언급률·경쟁사 비교는 자동 수집된 데이터 없이는 추적할 수 없다. 반면 콘텐츠 개선은 내부 인력이 실행할 수 있다. 입학처·홍보팀·각 학과 조교가 템플릿과 체크리스트에 따라 콘텐츠를 채우는 방식이 현실적이다.
결론 — 규모는 함정이 될 수 있다
"우리 사이트는 5,089페이지이고 AI 인용률 100%인데, GEO 점수가 49점이고 경쟁 대학에 밀린다." 이 문장이 성균관대학교 한 기관의 이야기가 아니다. 국내 주요 대학, 중앙부처, 공공기관, 대형 포털 대부분이 같은 상태다. 규모가 가시성을 만들지 않으며, 인용률이 점유율을 보장하지 않는다.
AI 시대의 공식 콘텐츠는 '많이 있다'는 것만으로는 충분하지 않다. AI가 추출할 수 있는 구조, 신뢰할 수 있는 메타데이터, 크롤링 가능한 접근성, 최신으로 유지되는 콘텐츠 — 이 네 가지가 함께 갖춰져야 비로소 "AI에게 잘 보이는 공식 콘텐츠"가 된다.
성균관대학교의 경우 GEO 종합 점수 49점에서 시작해, 답변 추출성·인용 권위·콘텐츠 신선도에 집중한 개선으로 80점대 진입이 가능하다. 이것은 단순히 점수 개선이 아니라, 수험생이 AI에게 "좋은 경영학과 어디?"라고 물었을 때 공식 사이트가 답변 안에 포함되는 빈도가 올라간다는 뜻이다. 그리고 그 빈도가 입학 경쟁률과 브랜드 가치에 직결된다.
지금 진단이 필요한 사이트가 있다면, 루미스캔(lumiscan.live)에서 GEO 4대 지표, AI 인용률, 프롬프트 모니터링, 경쟁사 비교를 한 번에 확인할 수 있다. 첫 진단은 무료이며, 5,000페이지 규모의 기관 사이트도 1~2분 내에 분석이 완료된다. 성균관대 케이스처럼 "AI가 이미 인용하고 있는데 왜 경쟁에서 밀리는가"라는 질문에 대한 구체적 답을, 당신의 사이트 데이터로 받을 수 있다.
출처·참고자료
Lumiscan GEO 4대 지표 진단: 성균관대학교(www.skku.edu) 2026년 4월 21일 분석 데이터
Princeton University & IIT Delhi, "GEO: Generative Engine Optimization", ACM SIGKDD 2024
EDUCAUSE, "Students and AI 2025 Study"
llms.txt 제안: Answer.AI (Jeremy Howard, 2024.11)
AI 인용 반감기 연구: 350만 건 인용 데이터 분석 보고서(2025)
Schema.org EducationalOrganization, Article, FAQPage, Organization 스키마



